【操作系统实验】ChCore lab2 - 内存管理
ChCore lab2 - 内存管理
实现内存管理部分。
1. 物理内存管理
为了提高内存资源的利用率,ChCore 以 4KB 即页大小为粒度进行物理内存的管理。同时采用伙伴系统(buddy system)进行管理。
伙伴系统
用于解决物理内存的碎片问题。将物理内存划分为若干个连续的块,以块作为基本单位分配。
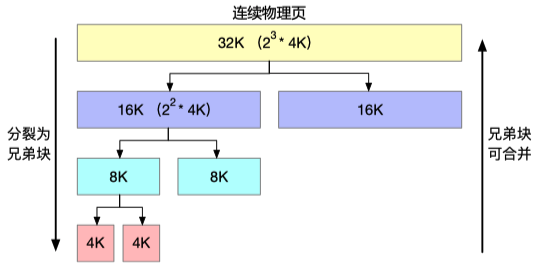
当需要请求分配 m 个物理页时,伙伴系统将寻找一个大小合适的块,该块包括 $2^n$ 个物理页,满足 $2^{n-1}<m\le 2^n$ 。
在处理分配请求的过程中,大块可以分裂成两个相等的小块,这两个小块互为伙伴。分裂得到的块可以继续分裂,直到得到一个符合条件的块来响应分配请求。
同时,当一个块释放时,分配器会找到其伙伴块,如果伙伴块也空闲,就会尝试向上合并。合并得到的块也会继续尝试向上合并,直到无法合并为止。
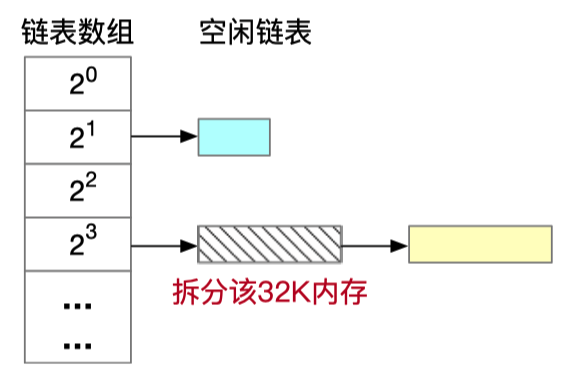
还有一个数据结构,用来保存释放的块:
物理内存布局
在实现伙伴系统之前,需要了解 Chcore 的物理内存布局。

Chcore 的物理内存地址的划分如下:
image_end以上的部分- page(分页数据)
- metadata(元数据)
image_start~image_end:- BOOT CODE&STACK 部分:用于 bootloader 的代码、数据和 CPU 栈。
- KERNEL IMAGE 部分:存放内核代码和数据。
image_start以下的部分是保留的(img_start被硬编码为 0x80000)
比较重要的部分是,page 和 metadata 是分开的。
实现伙伴系统
先实现 merge_page() 和 split_page() ,因为它们是实现申请和释放页的基础函数。
split_page() 函数
1 | static struct page *split_page(struct phys_mem_pool *pool, u64 order, |
merge_page() 函数
1 | static struct page *merge_page(struct phys_mem_pool *pool, struct page *page) |
buddy_free_pages() 函数
1 | void buddy_free_pages(struct phys_mem_pool *pool, struct page *page) |
buddy_get_pages() 函数
1 | struct page *buddy_get_pages(struct phys_mem_pool *pool, u64 order) |
2. 虚拟地址映射
虚拟地址无法直接用于寻址,需要先通过 MMU 转换为物理地址,才能使用。
所以这段代码实现的是 mmu 吗?
内核态与用户态隔离
为了保证进程的隔离,不同进程使用的页表不同,相同进程的用户态和内核态使用的页表也不同(aarch64 下)。 ARM 拥有两个页表基地址寄存器:
- TTBR0_EL1:用于存储用户态程序映射的页表;
- TTBR1_EL1:用于存储内核映射的页表。
虚拟地址的组成和翻译
内核态和用户态地址的区分
在 AArch64 中,虚拟地址的实际大小是 48 位(地址长度是 64 bit)。所以,地址的前 12 bit 都必须全是 0 (表示用户态)或者全是 1(表示内核态)。
内核态地址的翻译
页表采用 4 级索引的方式,如图所示:
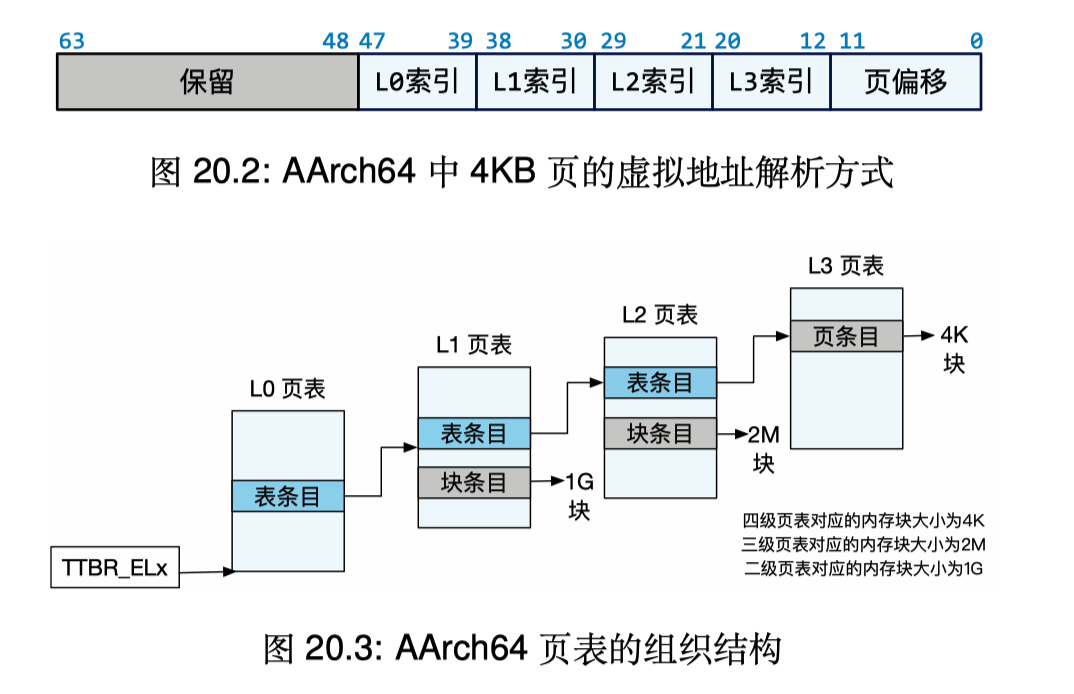
AArch 64 采用四级页表。每级页表的索引占据 9 bit,最后 12 bit 作为页面,构成 48 bit(4 * 9 + 12)。
页表中的每一项(条目)都被成为描述符。描述符分为三种:
- 表描述符:该描述符表示的是某个下一级页表的地址;
- 块描述符:描述一个内存块;
- 页描述符:描述一个内存页;
实现虚拟地址转换
get_next_ptp() 函数
先研究一下 get_next_ptp() 函数的实现:
从传入的虚拟地址 va 中取出对应页表的索引
index:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16switch (level) {
case 0:
index = GET_L0_INDEX(va);
break;
case 1:
index = GET_L1_INDEX(va);
break;
case 2:
index = GET_L2_INDEX(va);
break;
case 3:
index = GET_L3_INDEX(va);
break;
default:
BUG_ON(1);
}从索引找到对应的页表项:
1
entry = &(cur_ptp->ent[index]);
判断页表项是否启用(is_valid)
如果没有启用,则根据 alloc 参数,来选择是否申请一页内存来存放下一级页表。
1
2
3
4
5
6
7if (IS_PTE_INVALID(entry->pte)) {
if (alloc == false) {
return -ENOMAPPING;
} else {
// alloc a new page and set.
... ...
}从当前页表项中取出下一级页表(或者是页面)的地址,并返回
1
2
3
4
5
6*next_ptp = (ptp_t *) GET_NEXT_PTP(entry);
*pte = entry;
if (IS_PTE_TABLE(entry->pte))
return NORMAL_PTP;
else
return BLOCK_PTP;
map_range_in_pgtbl() 函数
先实现 map_range_in_pgtbl() 函数。根据注释:
功能:将虚拟地址段
[va:va+size]映射到指定的物理地址段[pa:pa+size]参数:
va:虚拟地址段的起始
pa:物理地址段的起始
len:地址段的大小
flags:相关的属性标志位
提示:需要先调用
get_next_ptp()函数来获得每一级页表的 entry,仔细阅读pte_t的定义,这样就会更容易调用set_pte_flags()来设置页面的标志位。函数最后别忘记调用flush_tlb()来刷新。
所以意思是:在调用这个函数之前,已经有了一页内存,但是还没有把它记录到页表上?
所以实现思路是这样:
先考虑从 va 到 pa 映射一页的情况,通过 get_next_ptp() 函数获取到每一级页表,在前三级页表(L0~L2)中调用 get_next_ptp() 时,将 alloc 参数设置为 true,表示页表项空缺的时候,分配一页物理内存来保存页表项。在第四级页表(L3)找到页地址时,alloc 参数设置为 false。因为认为在调用 map_range_in_pgtbl() 之前已经分配了一页,只需要将这一页地址记录到页表上就可以了。
在这一步还踩了坑。本来我觉得,在 L3 级调用
get_next_ptp()时 alloc 参数置为 false 即可,因为已经分配了物理页面,不需要在这里分配了,只需要将其对应的 pte 设置好,指向已分配的物理地址即可。但是很离谱:
2
3
4
5
6
if (alloc == false) {
// 当遇到 alloc = false 返回时,设置 pte
// *pte = entry;
return -ENOMAPPING;
} else {所以在这里我添加了一句
*pte = entry;,使得即使查找失败,也会返回 pte 供操作。
query_in_pgtbl() 函数
根据注释:
- 功能:给出虚拟地址 va,通过查询页表得到其物理地址 pa,并获得对应 pte 的标志位。
- 参数:
- pgtbl:第一级页表(L0)的地址;
- va:查询的虚拟地址;
- pa:保存查到的物理地址;
- entry:返回页面对应的 pte;
- 提示:注意检查
get_next_ptp()函数的返回值,如果是BLOCK_PTP说明找到的是一个大页。
以 L2 页表项为例:
1 | struct { |
is_table 标志位表示该项指向的内容是不是下一级页表。显然,如果下一级不是页表的话,就表示一个大页。
当一个页是 4K($2^{12}$)时,L2 级别的大页的尺寸就是 2M($2^{12+9}=2^{21}$,因为每一级页表的索引长度是 9 bit ),L1 级别的大页尺寸就是 1G($2^{30}$)。
unmap_range_in_pgtbl() 函数
比较简单,不写了。
3. 内核地址空间
虚拟地址空间被分为两部分:
- 用户态地址空间
- 内核态地址空间
ChCore 使用页表的权限标志位来保证用户代码只能访问用户态地址空间。
实现映射内核地址空间
1 | void map_kernel_space(vaddr_t va, paddr_t pa, size_t len) |
比较简单,直接调用函数就可以了。