【论文阅读】Semantic Crash Bucketing
Semantic Crash Bucketing
一、文章解决的问题
Crash 数量庞大。大量的 crash 可能指向了相同的漏洞,人工分析非常困难。
因此,需要自动化地将 crash 根据 “root cause”分类。
给出一组 crash,对这些 crash 按照不同的漏洞点进行分类。
二、已有的解决方案与缺陷
已有解决方案往往根据这些信息来对 crash 分类:
- 导致 crash 的程序输入 (input)
- 崩溃前的程序执行路径 (trace)
- 程序崩溃时的状态 (coredump)
- 以上信息的结合
具体的技术方案如下:
- Stack hash 与 分支序列技术:已经用于一些 fuzzer 中来对 crash 分类。但是它们过于不精确:
- 大量崩溃于同一 root cause 的 crash 并未正确识别到同一分类
- 部分不相同的 crash 反而被归到同一分类
- 基于符号执行/机器学习的分类:这种分类的精确性基于对语义特点的敏感性(比如符号分支的不同)(what??)
三、本文创新方案与难点
本文提出了一种识别不同漏洞(和其对应 crash)的方法——通过 patch 程序修复漏洞来识别。
原理:修复操作能够将导致崩溃的输入(crash input) 与导致崩溃的 bug 联系起来。原因是对 bug 正确的修复,将会导致触发相应 bug 的 crash input 不再崩溃。(显而易见的道理)
难点:修复 bug 是困难的,即使让开发人员手工修复也是困难的。
因此,文章提出了近似修复(approximate fixes)的概念,这本质上是一个妥协,但是“我们”认为,近似的修复已经足以帮助“我们”区分不同的 crash,而且近似修复还能节省开销。下面是一个近似修复的例子:

crash 崩溃的原因是对 zSpan 空指针引用。左侧是开发者给出的修复,右侧是文章提出的近似修复。可以看到,近似修复只是在引用前检查其是否为空指针,是则中止运行。
应用了近似修复之后,之前由于该空指针引用漏洞而崩溃的 input 在运行修复后的程序时,会执行 exit(101); 中止,而不再引发崩溃。而由于其他漏洞而崩溃的 input 则不受影响,继续崩溃。因此,得以区分出与此 bug 相关的 crash。
文中指出,这种做法可能是有缺陷的。当一个 crash input 可以触发两个位置的 bug 时,直接
exit将会掩盖第二个 bug 的信息。这一点作者表示将是未来的研究点。
总结:本文的贡献如下:
- SCB(Semantic Crash Bucketing): 一种根据更改程序语义自动识别独特错误的新颖技术
- 近似修复(Approximate Fix):使用 bug 修复模板和基于规则的修复策略来自动修复漏洞(近似修复的效率更高)
- 实验评估
四、框架概述
基于第三部分提到的,本文的贡献是 SCB 和 近似修复,下面分别介绍这两点。
Sematic Crash Bucketing 过程
基本概念:
- $P$ : Program
- $b_i$ : 对于漏洞点 i,它与一系列 crash 相关联,$b_i$ 是这一系列 crash 的集合
- $T_i$ : 对于漏洞点 i,$T_i$ 表示对漏洞点 i 的 patch
- $B_{fuzzer}$ : 表示 fuzzer 返回的一系列漏洞 buckets
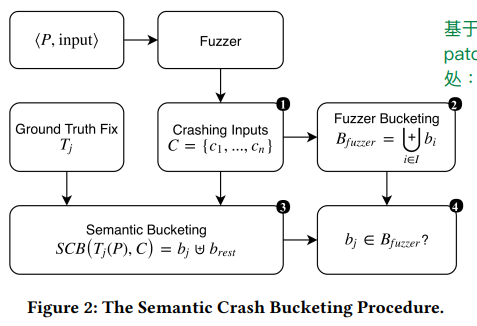
- fuzzer 输出了一系列 crash,记为集合 $C$
- fuzzer 对集合 C 预先进行了一次分类。$I$ 表示 fuzzer 认为的漏洞集合,fuzzer 按照每个漏洞相关的 crash 进行分类,即 $B_{fuzzer}=\bigcup\limits_{i\in I}b_{i}$
- 应用 SCB ,使用一个可靠的修复 $T_j$ ,然后用集合 $C$ 中的所有 crash input 进行测试,分类得到 $b_j$ (不再崩溃的输入集合) 和 $b_{rest}$ (仍然崩溃的输入集合)
- 验证 $b_j$ 是否是 $B_{fuzzer}$ 中的一个元素,来检查 fuzzer 的分类是否正确。
生成近似修复
首先必须承认,开发者修复是最好的,采用近似修复是性能和复杂度上的妥协。但是使用近似修复并不影响 SCB 系统的精确,因为近似修复足以对 crash 是否关联于这个漏洞作出区分。
本节讨论的主要内容是,如何生成对一个漏洞的近似修复。
本文提出的近似修复生成方法,可以针对两种漏洞类型进行修复:
- 空指针引用
- 缓冲区溢出
空指针引用漏洞的近似修复
当找到空指针引用漏洞后,直接应用一个下面所示的简单修复:
1 | if (%%%PVAR%%% == NULL){ |
即检查其是否是空指针,是则直接中止程序运行。这其实是一个保守的策略,但作为 crash 的区分足够有效。
难点:where to patch? 或者说如何定位到空指针引用漏洞的位置?需要正确推测出 PVAR 的值
解决方案:通过 GDB trace。具体做法如下:
- 将 gdb 附加到进程上,运行 crash input
- 提取程序的源代码,报告 crash
- 解析源码中的空指针引用
- 提取出指针变量 PVAR,在解引用之前添加 patch,然后测试 patch 是否有效。
- 如果无效,则回退到步骤 3 ,向前寻找一个基本块,重复此操作
缓冲区溢出漏洞的近似修复
和空指针引用漏洞不同,溢出的位置可能更早,因此不能再按照先前的原则修复。
本文提出的方法是,对 C library 中的内存写函数进行 patch,例如 memcpy,strcpy,sprintf,gets,strcat 等。
以 memcpy 为例,修复模板如下:
1 | // Modify a possible overflowing memcpy call |
这里不再是插入代码,而是修改代码。强行将 memcpy 的 size 设置为 1,这样显然不会再溢出了。具体的分析流程如下:
难点:找到上述库函数的调用点,还需要分析出调用点的参数(例如 memcpy 的 src 和 dst 参数)
解决方案:
- 使用 ltrace 来得到 crash input 运行过程中的 library 调用
- 回退分析,解析库函数调用的源码位置,找到我们能应用修复模板的位置(Working backwards, resolve the source location of library calls in the trace for which we have fixing templates.)
- 应用修复模板
- 如果修复成功(不再崩溃),则返回修复结果,否则回到第二步
我觉得第二步写得不清晰,但我推测是找到源码中对上面提到的这些,可能导致溢出的库函数的调用,然后依次对每个调用 patch,检查是否崩溃。
文中提到了对 memcpy 的修复模板,事实上还有很多修复模板,甚至也允许用户手动提交修复模板。
五、实验
挖坑
六、总结
SCB 的局限性:
- 前期需要人工调参
- 漏洞类型的复杂性使得修复模板和语义暗示(semantic cue)的复杂性增加
- 近似修复仍然对精度有影响
我个人的理解是:
SCB 最大的创新点在于,通过修复漏洞的方式来对漏洞关联的 crash 进行识别和区分。虽然文中也提到不能处理”一个crash input 能触发两个漏洞“的情况,但是我认为无伤大雅。
但是后续为了实现 SCB 而进行 patch 的做法则显得有些粗糙,主要包括两点:
一、文中只提出了对空指针引用漏洞和缓冲区溢出漏洞处理,虽然这两者足以覆盖多数漏洞,但是据我所见,fuzzer 提供的 crash 可能导致对非法地址的引用,而不一定是空指针。所以我认为文中对漏洞修复提供的支持不够。(也可能受限于时间,工作量等,我不确定这是否是一个合理的妥协)
二、对于缓冲区溢出漏洞近似修复并不合理。强行限制写入长度为 1 可能会引入新的错误,例如结构体复制时并未完全复制,后续的引用可能就会出错,而原本的 crash input 并未触发这个由 patch 而引入的错误。此外,遍历库函数引用,并依次 patch 也绝不是一个好的选择,至少应当基于控制流或数据流进行一定的分析来决定 patch 哪个函数的引用。(同理,我也不确定这是否是一个合理的妥协)