【论文阅读】REPT: Reverse Debugging of Failures in Deployed Software
REPT: Reverse Debugging of Failures in Deployed Software
一、文章解决的问题
开发者只能基于少量信息来调试错误。通常情况下只有 coredump 文件,而对于调试崩溃很有意义的 trace 信息则很难获取,常用的插桩方法会引入大量开销。因此,作者希望提出一个辅助崩溃分析的工具。
二、已有的解决方案与缺陷
已有的针对崩溃分析的工具可以粗略地分为两类:
自动化的 root cause 诊断:尝试自动化地找到导致崩溃的程序语句。
局限性:这些工具要么需要修改源代码,要么不能处理复杂类型的漏洞崩溃,且很难部署。此外,就算找到了 root casue,也需要对这些语句有一个更深入的分析才能修复漏洞,而这些工具并不能深入理解崩溃的核心原因。
错误复现:尝试让开发者能够分析导致崩溃的输入和程序状态。
- 符号执行,模型检查,状态空间探索等技术可以用于确定导致崩溃的input。但他们在运行时会带来高开销。
- 记录-重放系统 可以记录程序的执行,然后重放来debug。(gdb reverse debugging?)
优点:允许开发者从崩溃执行向前和向后分析,辅助理解漏洞原因并给出修复
缺点:带来极大的开销(200%)
综上所述,需要一个可行的解决方案,使得逆向debug错误可行,必须满足:
- 运行开销小
- 必须能够准确快速地恢复执行历史
- 对未修改的代码/二进制程序分析
- 适用于多种漏洞类型
三、本文创新方案、框架与难点
为了解决上述问题,文章提出了工具 REPT,一个能够对已部署系统中的软件故障进行逆向调试的可用系统。
REPT 通过两个步骤来实现逆向崩溃调试:
- 使用硬件追踪来记录程序的控制流,减小开销(在线 (online) 的轻量级硬件追踪控制流)
- 使用新颖的二进制分析技术,基于记录下来的控制流信息和coredump文件来恢复数据流(离线 (offline) 的二进制分析进行数据流恢复)
难点:
- 如何精确高效地恢复数据流信息:控制流可以通过 Intel PT 等硬件提供,但是数据流无法记录。原则上我们只能得到崩溃时的 coredump 文件。因此必须找到一种方式,来恢复崩溃之前的程序状态(数据流信息)
- 首先,我们拥有 coredump 文件,能够知道崩溃时的内存布局与寄存器值(最终状态)
- 如果每条指令都是可逆的(比如数学指令),我们就可以容易地推出执行这条指令之前的程序状态(指内存值与寄存器值)
- 但显然,并非所有指令都是可逆的,比如 mov 指令就会覆盖之前的内存信息。因此论文提出了一种正向与反向执行结合的技术来恢复数据流。
- 多线程执行时,恢复数据的读写是非常困难的。因此必须能够区分多线程执行时内存的访问顺序。
- REPT通过基于硬件记录的时间戳构造部分执行顺序
总结:为了实现逆向执行技术,作者提出了两点:正向与反向执行结合,与基于硬件记录的时间戳构造部分执行顺序
四、技术细节
要通过逆向执行来实现数据流恢复,需要解决三个问题:
处理不可逆指令:(例如:
xor eax, eax)解决方案:通过正向执行来恢复反向执行无法恢复的数据
未知内存地址写:(例如:
mov [esi], ecx,当没有分析出 esi 时,就是未知内存地址写入)解决方案:使用错误纠正技术
识别共享内存的访问顺序:多线程状态下的访问顺序
解决方案:基于硬件时间戳。
正向与反向执行结合 (combine forward and backward execution)
定义:
- $I = {I_i| i = 1,2,\dots,n }$ 表示指令序列,$I_i$ 表示指令序列的第 i 条指令。
- $S$ 表示程序的状态(所有内存数据与寄存器值),$S_i$ 表示第 i 条指令执行之后的程序状态,因此 $S_0$ 表示程序在执行指令 $I_1$ 之前的状态,而 $I_n$ 表示程序崩溃时的状态(coredump)
- 如果状态 $S_i$ 的所有内存值和寄存器值都是已知的,那么我们称状态 $S_i$ 是完整的。
- 如果给定一个完整的状态 $S_i$ ,可以恢复状态 $S_{i-1}$ ,那么称指令 i 是可逆的。
在反向执行过程中,针对不可逆的指令恢复数据,核心思路是应用正向执行。具体做法如下:
给定指令序列 $I$ 和最终状态 $S_n$:
- 将 $S_0\sim S_{n-1}$ 的所有寄存器值设置为未知
- 进行反向分析来恢复寄存器 $S_{n-1}\sim S_{0}$ 的值
- 执行正向分析来更新 $S_0\sim S_{n-1}$ 的程序状态
- 重复2.3.直到正向和反向分析没有状态更新为止。
下图是一个具体例子。其核心就是正向分析与反向分析迭代,比较简单所以不解释了。
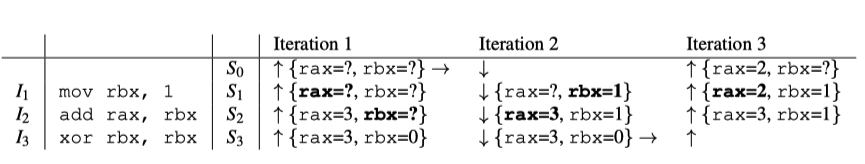
未知内存地址写问题 (Missing Memory Writes)
上述例子只是考虑了不可逆的指令。但是还会遇到未知内存地址写问题。REPT 采用的办法是:继续使用可能有效的内存值来推断其他值,并在以后根据冲突发现值无效的情况下更正这些值。
个人理解:先暂时放着不管,以后遇到冲突的时候更正
下面是未知内存地址写问题的一个例子,并对这个例子的冲突进行详细解释:

首先是 Iteration 1,是反向执行。在从 $S_5$ 向 $S_4$ 回推时,我们无从得知 rbx 的值是多少(因为 $I_5$ 清除了 rbx 的值,是不可逆指令)。因此从 $S_4$ 向 $S_3$ 回推时,我们也无从得知 [rbx] 指向哪一块内存地址,这是一个未知内存地址写。
当存在未知内存地址写时,一种做法是立刻将所有内存地址都设置为未知(因为每个地址都有可能被写),但是这样假设有些过于保守了。因此 REPT 的做法是先放着不管,假设什么都没发生,等待后续发生冲突时再纠正。
由于我们不知道 [rbx] 和 [g] 是否是同名变量,所以也无法确定 [g] 的内容是否被改写。这一点在从 $S_4$ 向 $S_3$ 回推时会暴露出来。
pomp 处理这个问题的方式是提出两个截然相反的假设,并依次验证;而 rept 的解决方案是先放着不管。
其次是 Iteration 2,是正向执行。从 $S_2$ 向 $S_3$ 执行的时候发生了冲突:$I_3$ 指令是
add rax, [rbx],根据 $S_2$ 的信息,rax+[rbx]=4,所以应当将 rax 的值设置为 4 才对。然而这个时候 rax 的值在 Iteration 1 中已经被回退分析为 3 了。这个时候就发生了冲突。(我们假设状态 $S_5$ 是完整状态,它的每个值都是可靠的,所以回退分析得到的 rax=3 也是可靠的,因此我们排除了 rax=4 的推测。后面会专门解释,当遇到冲突时,是选择采用新推测的值还是沿用旧推测)最后是 Iteration 3,又是反向执行。这里状态 $S_2$ 被更新为 2,比较简单。
Iteration 3 这里我个人认为图画的不规范。首先是状态 $S_3$ ,[g] 仍然应该被设置为 3,因为这里并未发生冲突。这里冲突应该发生在 Iteration 4,因为 $S_2$ [g] 被设置为 2,传递给 $S_3$ 的时候会发生冲突。这里可能是作者懒得画 Iteration 4 了?
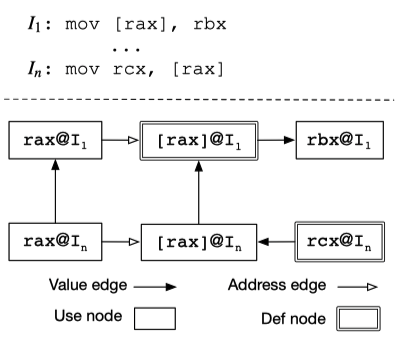
数据推测图 (Data Inference Graph)
在上一节中,提到了“当遇到冲突时,选择采用新的值还是沿用旧推测”。本节将提出选择依据。
数据推测图中的每一个结点都表示一个被某条指令访问的寄存器或内存地址。显然,一条指令可能会产生多个结点。下面是一些定义:
- 引用结点:如果这个寄存器或地址被用于读操作,则这个结点称为
引用结点。 - 定义结点:如果用于写操作,则这个结点称为
定义结点。 - 值边 (value edge) :如果 REPT 使用结点 A 的值来推测结点 B 的值,那么从结点 A 到结点 B 的这条边称为值边;
- 水平边 (horizontal edge):当被连接的结点归属于同一条指令时,他们之间的值边被称为水平边。
- **垂直边 **(vertical edge) :当被连接的结点属于不同指令时,他们之间的值边被称为垂直边。
- 地址边 (address edge) :如果 REPT 使用结点 A 的值来计算结点 B 的地址,那么从结点 A 到结点 B 的这条边称为地址边。
当进行正向/反向分析时,每当设置或引用内存地址的值时,就会在对应的结点间添加一条地址边。一个内存使用结点可能被多个地址边指向(因为内存使用结点可能需要寄存器和索引值来计算出地址)。下图就是一个数据推测图。
个人认为,数据推测图是针对定值-引用链的强力扩充
对于每个结点,额外保存一个解引用等级 (dereference level) 来辅助错误纠正。直觉上来说,解引用等级表示从最终状态 $I_n$ 回退,直到目标结点时最多经历了多少条地址边(解引用了多少次)。解引用的次数越多,说明被推测的次数越多,推测的结果越不可靠。每个结点的解引用等级计算方法如下:
对 coredump 的值引用的使用结点的引用等级都是 0,其他引用等级判断方法如下:
对所有要到来的值边,找到其源结点的最大解引用等级 $D_1$
对于所有要到来的地址边,找到其源结点的最大解引用等级 $D_2$
在 $D_1$ 和 $D_2+1$ 中选择一个较大的值作为目标结点的解引用等级。
个人认为本节中对于如何构建一个数据推测图的描述并不清晰。应该给出一个例子一步一步解释图的构建。挖个坑。
错误修正 (Error Correction)
在“未知内存地址写问题”一节中,提到了“推测的值发生冲突”这一情况。本节介绍如何修正冲突。
有两种类型的不一致:
- 值冲突 (value conflict):推测的值与已有的值不同
- 边冲突 (edge conflict) :新识别的内存地址定义结点打破了之前假设的通过垂直边连接的两结点的定义引用关系
值冲突比较好理解;边冲突的一个例子是:针对数据推测图一节中对例子,如果 REPT 检测到在 $I_1$ 到 $I_n$ 之间对 [rax] 有写入指令的话,就会破坏 [rax]@In 和 [rax]@I1 之间的垂直边。
错误修正的方式也比较容易理解:
- 对于值冲突,检查冲突结点之间的解引用等级,保留解引用等级较小的,丢弃解引用等级较大的。
- 对于边冲突,直接断开原有的垂直边,连接新的垂直边即可。
处理并发问题(Handling Concurrency)
挖坑。
五、实验
挖坑。
六、总结
挖坑。