【论文阅读】POMP: Postmortem Program Analysis with Hardware-Enhanced Post-Crash Artifacts
POMP: Postmortem Program Analysis with Hardware-Enhanced Post-Crash Artifacts
我喜欢这篇文章。因为国人写的英语我能看懂。
一、文章解决的问题
手工分析 crash 是一项繁重的工作。我们需要一些自动化工具来辅助 crash 分析。而 POMP 就是一个能够准确且有效找出程序中和 crash 相关语句的分析工具。
给出一个 crash,分析该 crash 的 root cause
二、已有的解决方案与缺陷
记录-重放分析 和 coredump 分析是最常见的分析技术。
- 人工分析:分析与 crash 有关的程序代码,找到导致错误的值(比如非法指针值)是如何传递的
- 记录-重放 (record-play):通过插桩记录执行时的内存访问等操作,然后基于这些信息来重现这次执行
- 优点:完全重现控制流和数据流
- 缺点:基于插桩将引入高开销
- coredump 分析:针对崩溃产生的 coredump 进行分析
- 优点:开销小,因为信息都保存在 coredump 文件里了
- 缺点:core 文件只是提供了一个内存快照,只能推测部分控制流和数据流,因此不是最优解
然而,由于最近(指 2017 年的最近)Intel PT(Processor Tracer) 的发布,使得 coredump 文件可以包含崩溃前程序的执行路径(trace),因此,我们不再需要从插桩就能得到控制流信息(trace)。然而,即使有了 trace,也不足找到 root cause。想要有效地分析崩溃的根本原因,需要静态分析与动态分析的同时构建控制流和数据流信息,原因如下:
单纯的静态分析对内存损坏错误(缓冲区溢出,UAF)的分析很有限,因为内存损坏错误可能会被攻击者利用,从而修改控制流和数据流,破坏了其控制流与数据流的完整性。
三、本文创新方案与难点
提出逆向执行机制,将 coredump 文件作为输入,通过逆向执行分析 trace,构建崩溃前的数据流结构,借助回退污点分析 (backward taint analysis) 找到导向崩溃的关键指令 (critical instructions)。
难点:
一、Intel PT 向 coredump 文件提供了 trace,但是完整的执行路径可能包含 10 亿 (原文确实是 a billion) 条指令。即使仅分析崩溃前的部分指令,也有数千条指令需要分析。
二、就算只需要分析少数指令,对于手工分析来说也很困难。下面考虑一个手工回退分析的例子:
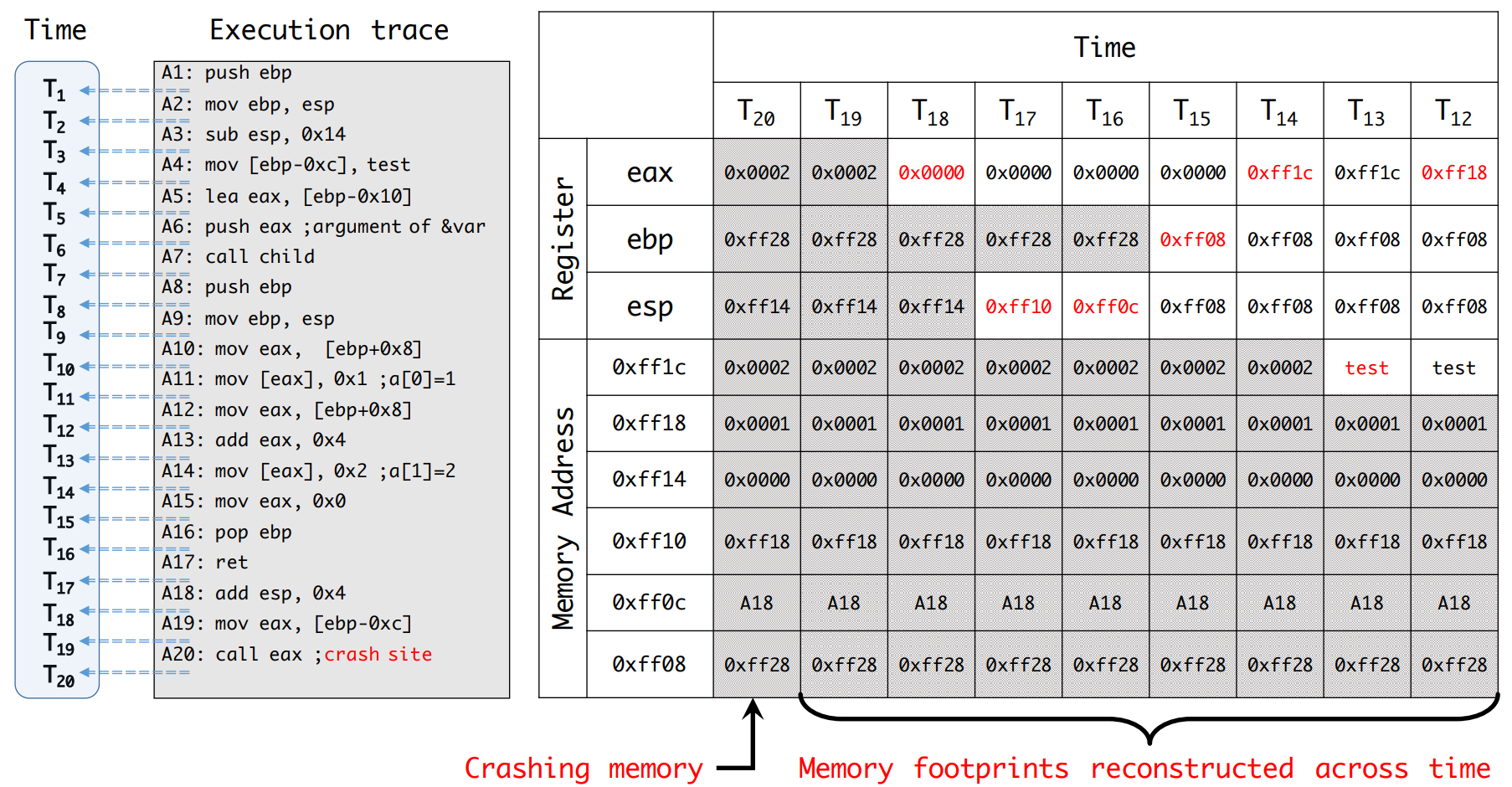
考虑指令 A19,我们很难知道在执行 mov eax,[ebp-0xc] 之前,eax 的值究竟是什么。概括地来说,mov 指令和数学指令( add , sub 等)不同,它是不可逆的指令。我们需要别的方法来恢复丢失的信息。
引用-定值链 (use-define chain):设变量 x 有一个定值 d,该定值能够到达的引用 u 的集合称为 x 在 d 处的引用-定值链。
通过构建引用定值链,就能够知道,A15 对 eax 的定义可以到达 A18,因此 T18 时刻 eax 的值是 0x0。
但是,仅构建数据流分析也不足以完成分析。我们再考虑一个例子:对指令 A14 进行逆向分析,就必须知道执行 A14 前 eax 的值,以及对应的 [eax] 的值。这里出现了一个问题:[eax] 和 [ebp+0x8] 是否为内存中的同名变量(内存别名 memory alias,即指向同一块内存的不同变量引用)?
- 如果它们不是同名变量,那么后面如果再引用到变量 [ebp+0x8] 时,则需要从 A12 指令继续回推
- 如果它们是同名变量,那么后续引用变量 [ebp+0x8] 时,A14 就是 [ebp+0x8] 的新定值
由此可见,内存别名问题会影响到引用-定值链的分析。如果需要得到合理的引用-定值链,需要解决别名问题。文章中提出了一种新的解决方案:假设测试方案(hypothesis test)。
假设测试 (hypothesis test):当需要判断两个变量是否是内存同名变量时,提出两个假设:
- 假设它们是内存同名变量
- 假设它们不是内存同名变量
然后,分别测试这两种假设是否成立,剔除掉不成立的假设,保留合理的假设。
综上所述,本文的贡献如下:
- 提出 POMP,一个基于逆向指令执行分析崩溃原因的工具。为了实现逆向指令执行,恢复每条指令执行前的内存布局(memory footprint),应用两个技术:
- 构建引用-定值链:设计了一个递归的逆向执行算法
- 内存别名识别:通过假设测试识别内存别名
- 在 32 位 Linux 下实现了 POMP
- 证明了 POMP 的有效性
四、框架概述
POMP 主要有两个部分:
- 逆向执行系统
- 内存使用恢复
接下来详细介绍这两个部分。
逆向执行系统(Reverse Execution)
POMP 的逆向执行算法主要分为两个步骤:
- 构建定值-引用链
- 识别内存别名
构建引用-定值链(use-def chain)
核心:解析 trace,对于 trace 中的每一条指令,提取这条指令相关变量的定值引用关系,形成一个结点,并将这个结点链接到之前构建的定值引用链上。
一个 def/use 结点由三部分组成:(指令ID(地址),use/def flag,值)
此外,每次在 ud 链上添加一个新的结点时,都会进行一次解析,来检查是否满足下面这些条件之一:
- 这个结点的 def 或者 use 信息能否到达链表的底端;
- it could reach its consecutive use in which the value of the corresponding variable is available; (???没懂)
- a corresponding resolved definition at the front can reach the use of that variable(**也没懂)
- 这个结点的值能否直接由当前指令的信息推导出来(
mov eax, 0x0这种指令就直接使用了立即数,所以我们能立刻推导出 eax 的结果。)
下面举一个例子,仍然用前面的例子,部分指令如下所示:
1 | ... ... |
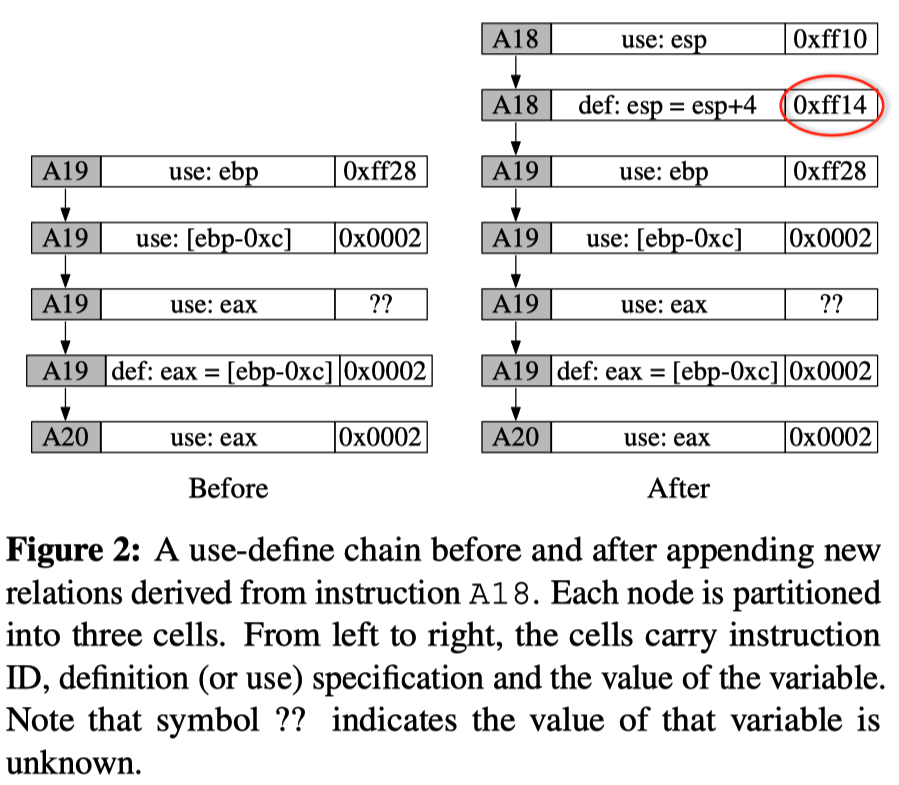
当前需要逆向分析的指令是 A18。在分析完指令 A18 之前和之后,定值引用链的变化如下图所示。流程为:
对指令
add esp, 0x4产生两个结点:def: esp += 4和use: esp首先处理 def 结点:沿 ud 链向下寻找第一个对 esp 的 use 结点,即类似于
use: esp。强调第一个的原因是只有第一个 use 才能传递到当前结点,后续的 use 已经被这次的 def 杀死了。然而这次寻找并没有找到一个这样的 use 结点,最终找到了链底部。说明本次def: esp += 4直接使用了 coredump 的 esp 值。在红圈位置填写 coredump 的 esp 值:0xff10然后处理 use 结点。当前指令
add esp, 0x4是可逆的。所以我们可以推导出执行这条指令之前 esp 的值是 0xff10。use 结点的值就是 0xff10。如果该指令不可逆,说明我们无法根据当前信息得出 use 结点的值,就会先填上??。添加完这两个结点后,下一步就是将这两个结点的信息传递到整个链上。沿 def 结点向后寻找,是否有后续的结点使用了 esp,即类似
use: esp, ??的结点。如果有,就将它的值同步为 0xff14。同步后还需要再次将这个信息继续同步。递归地进行信息地补全,直到链不再发生变化为止。(当然,对这个例子来说,并没有什么要同步的)这样看起来好像到达定值分析的过程
五、实验
待续
六、总结
待续