【PWN基础】栈溢出基本原理
栈溢出基本原理
一、函数调用栈
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等。
栈由高地址向低地址扩展。(相对,堆由低地址向高地址扩展)
下图展示了函数调用发生和结束的时候发生的变化。调用函数,就向低地址扩展一个新的区域,作为被调函数栈。
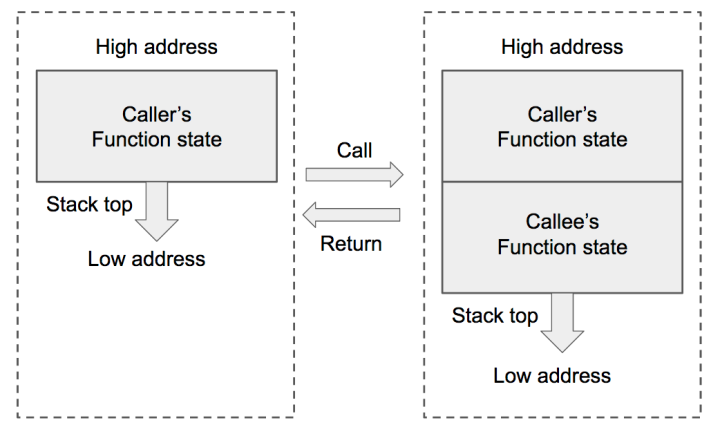
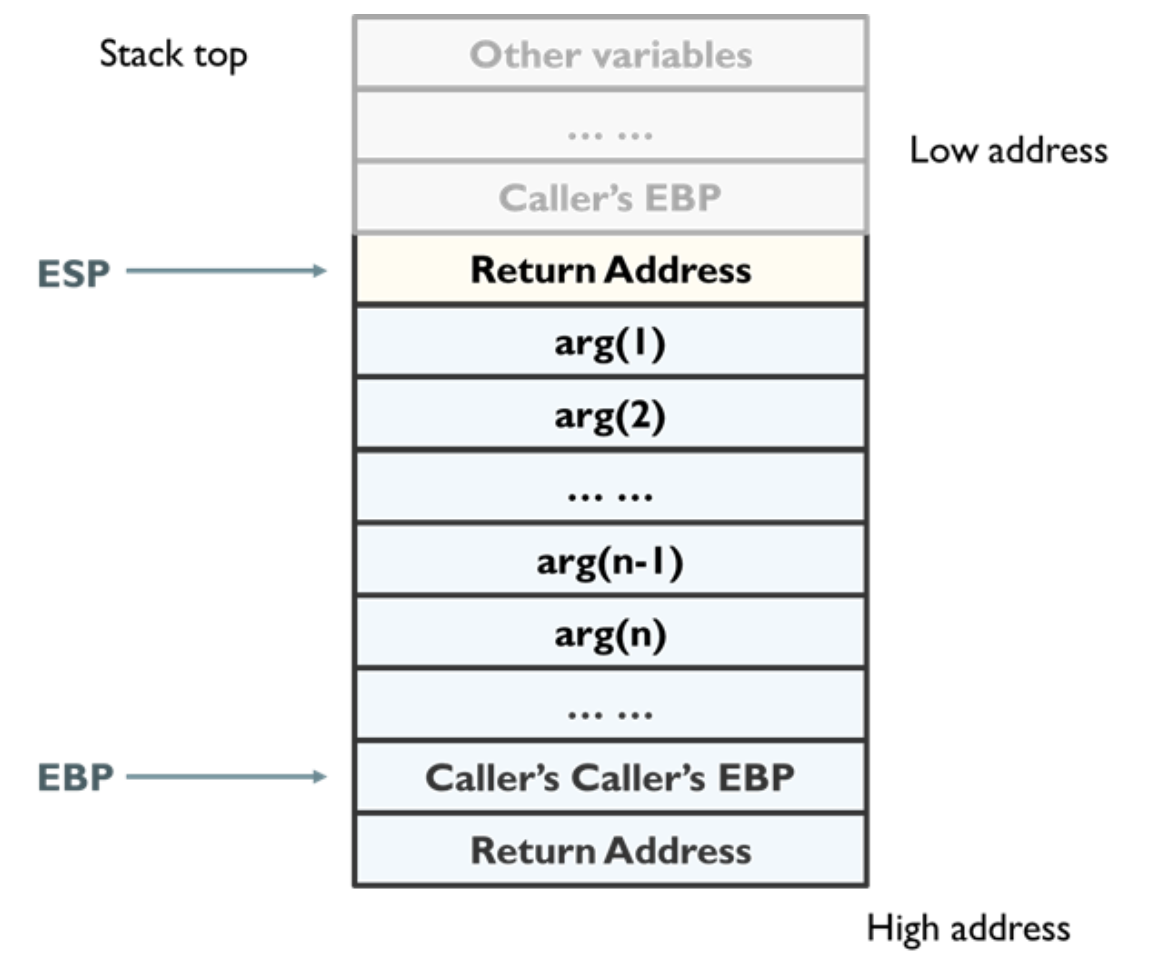
函数栈的状态主要涉及三个寄存器——ESP,EBP,EIP。
ESP:栈顶地址
ESP:栈底地址
EIP:指向下一条执行的指令(PC)
下面讲解函数调用时,栈顶函数状态以及上述寄存器的变化。
1. 将参数倒序压入栈中
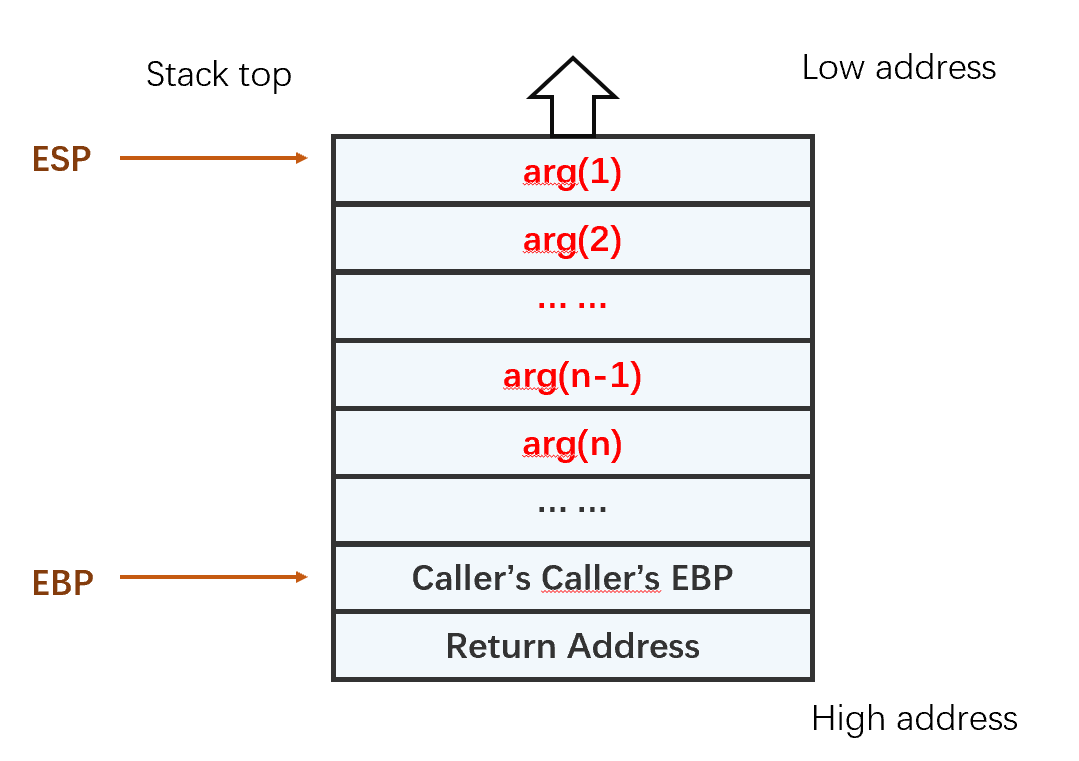
注意:32位机和64位机的区别:64位机首先用寄存器传参。前六个参数被传入RDI,RSI,RDX,RCX,R8,R9,其余的参数再压入栈。
2. 压入返回地址
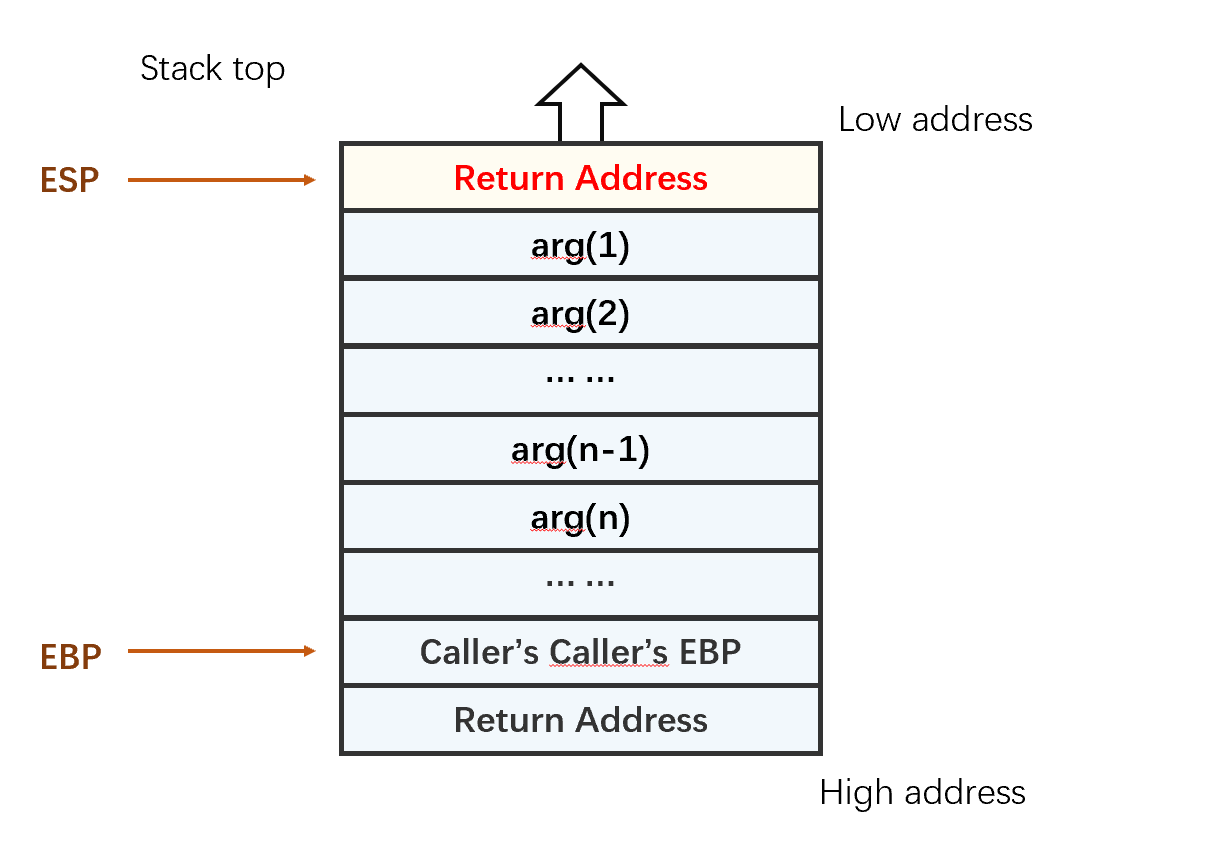
将调用函数进行调用之后的下一条指令地址作为返回地址,压入栈中。目的是保存caller的eip信息。
3. 压入caller的栈基地址,并修改EBP
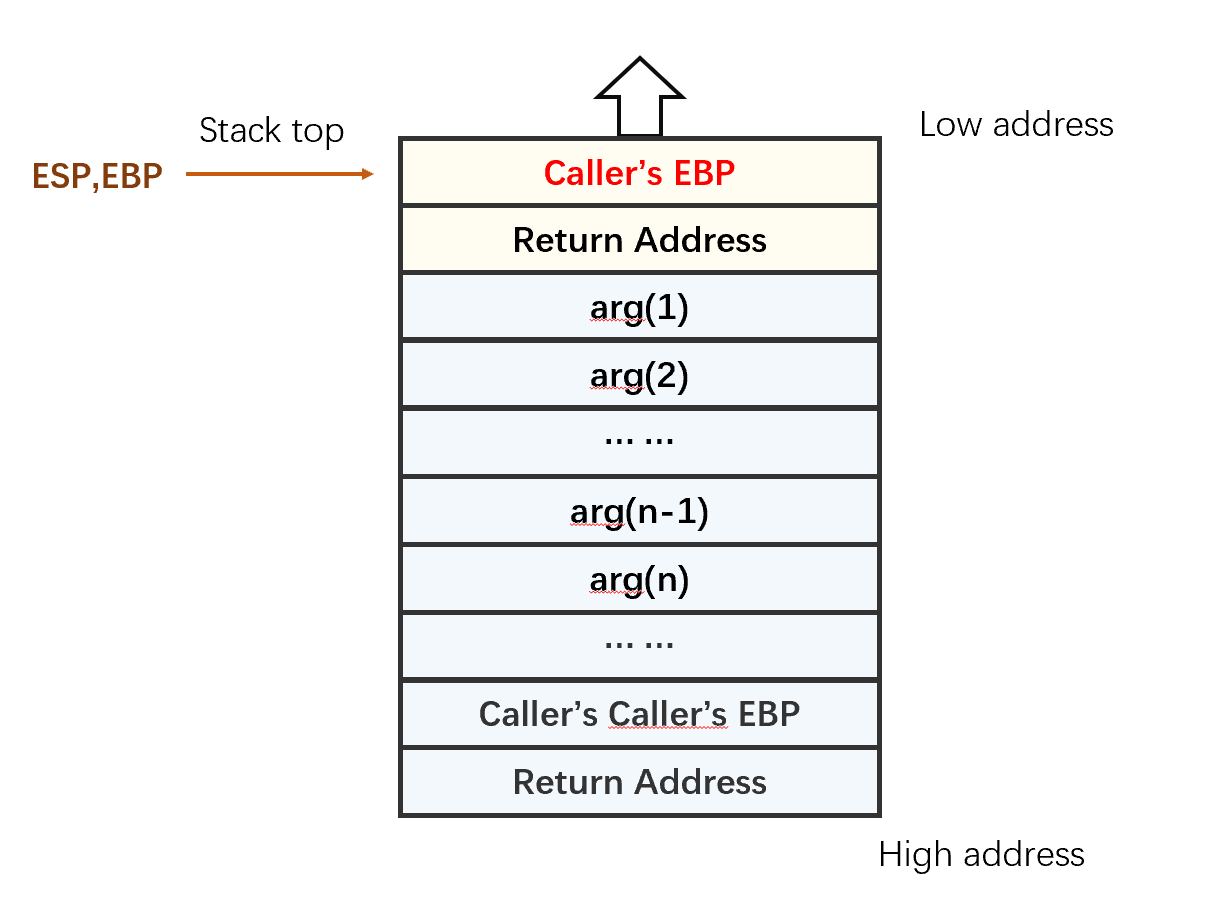
将调用函数的基地址(ebp)压入栈内,并将当前栈顶地址传到 ebp 寄存器内
再之后是将被调用函数(callee)的局部变量等数据压入栈内。
4. 进入函数执行
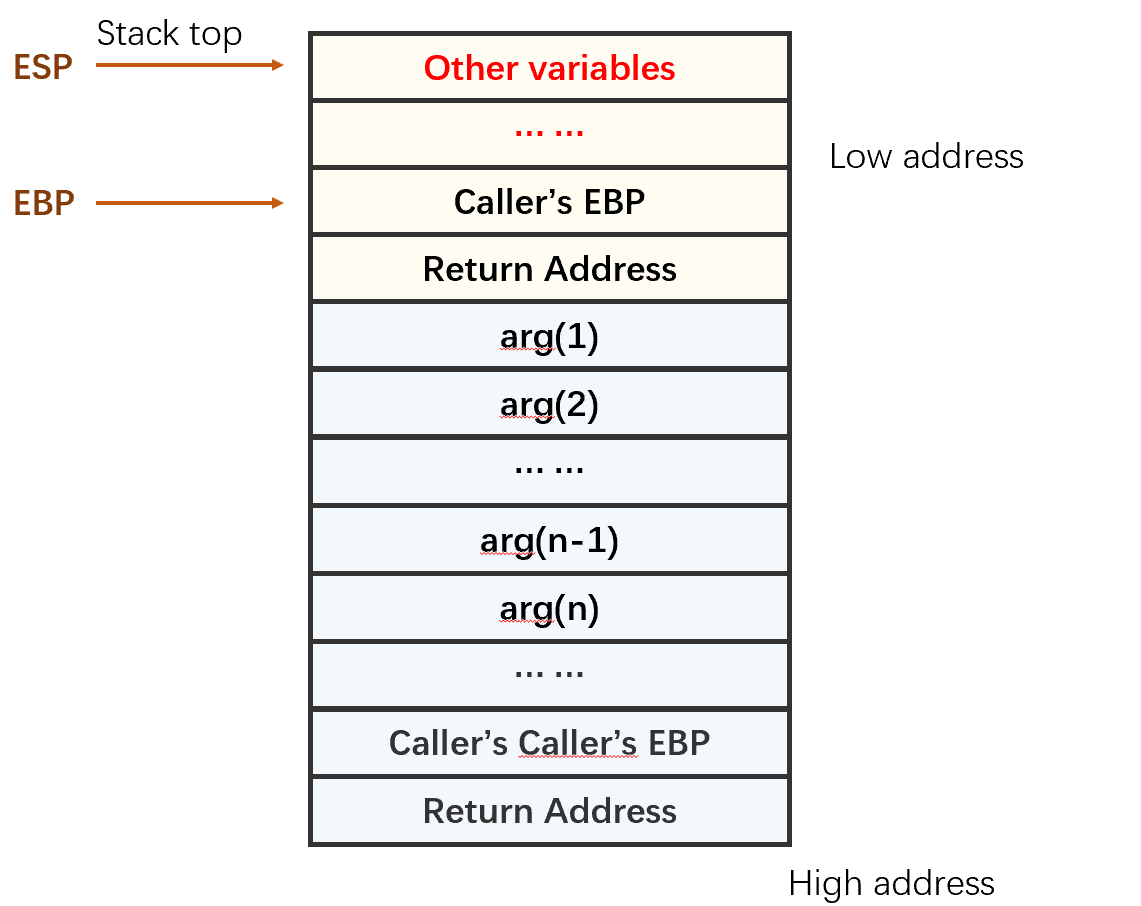
抬高ESP,为新的函数栈留出空间,保留新函数的临时变量。新函数能使用的空间在ESP到EBP之间。EBP不会移动,保证之前栈中的临时变量不会被改变。
5. 将被调函数的局部变量弹出
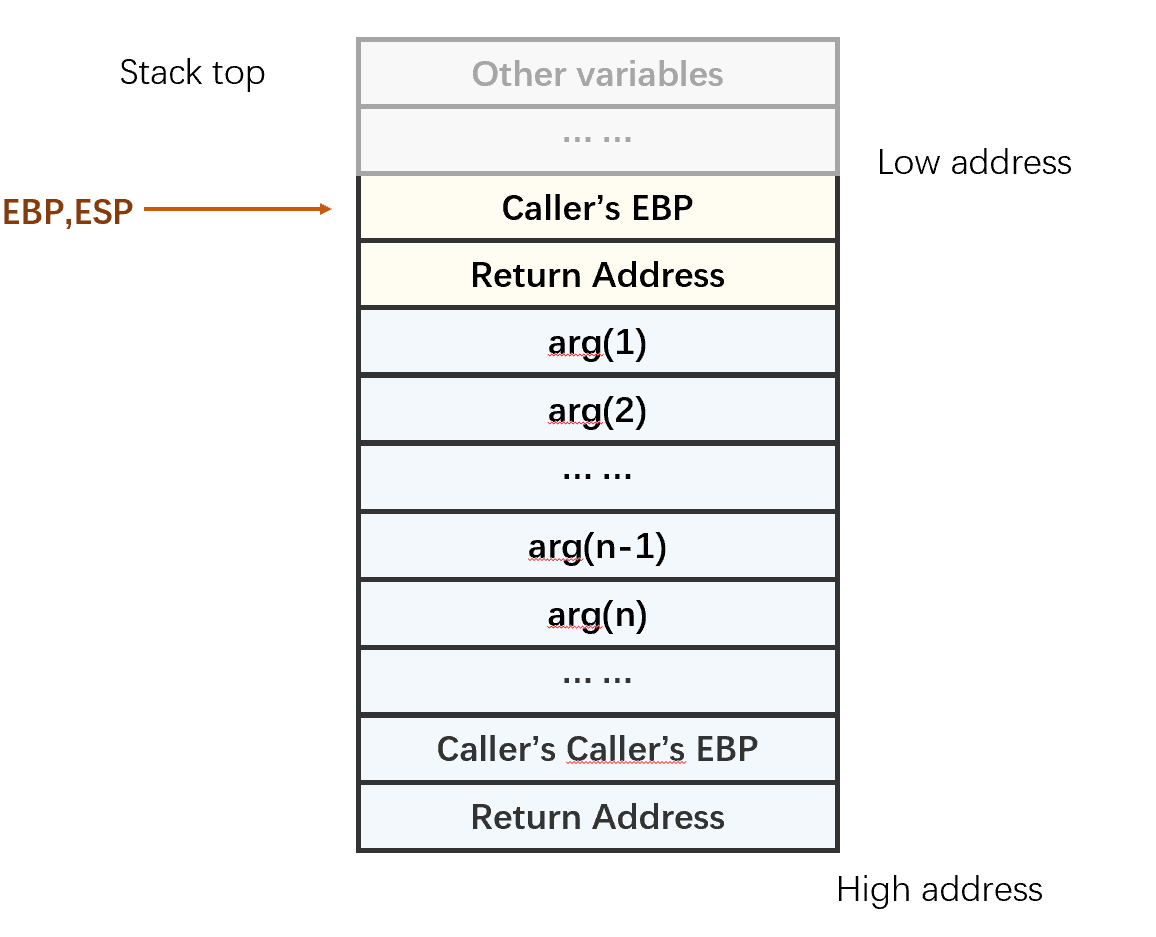
把ESP挪到EBP的位置,之前ESP和EBP之间的变量都作废。
6. 将主调函数的EBP恢复
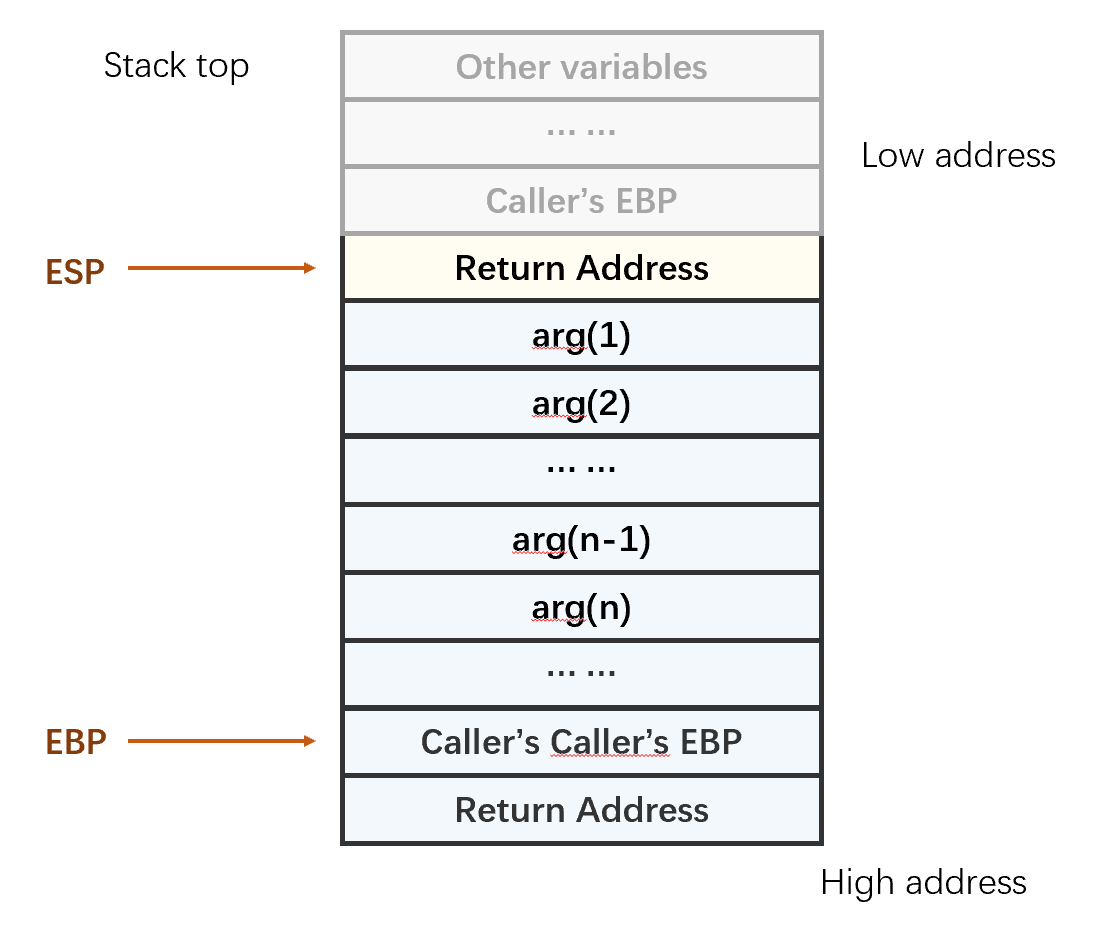
将主调函数的栈基地址从栈中取出,保存到EBP寄存器内。此时栈顶指针ESP指向返回地址。
7. 取出返回地址,赋值给EIP
二、栈溢出原理
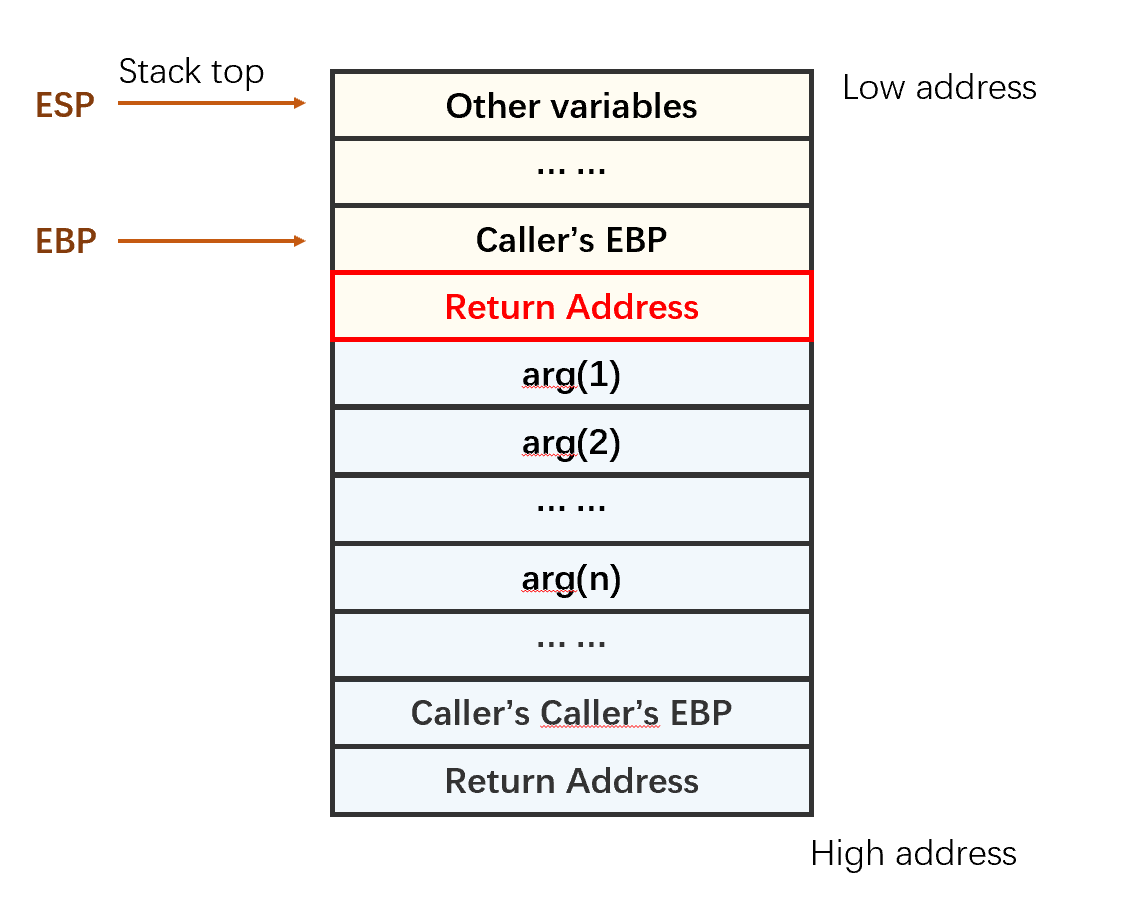
目的:控制程序流,即让EIP载入攻击指令的地址。
如果我们能在函数返回之前,修改Return Address的值,就能让EIP跳转到我们指定的位置。如果我们写入了一段shellcode,并把Return Address这个位置的值修改为shellcode的地址,那么函数返回时就会执行shellcode。
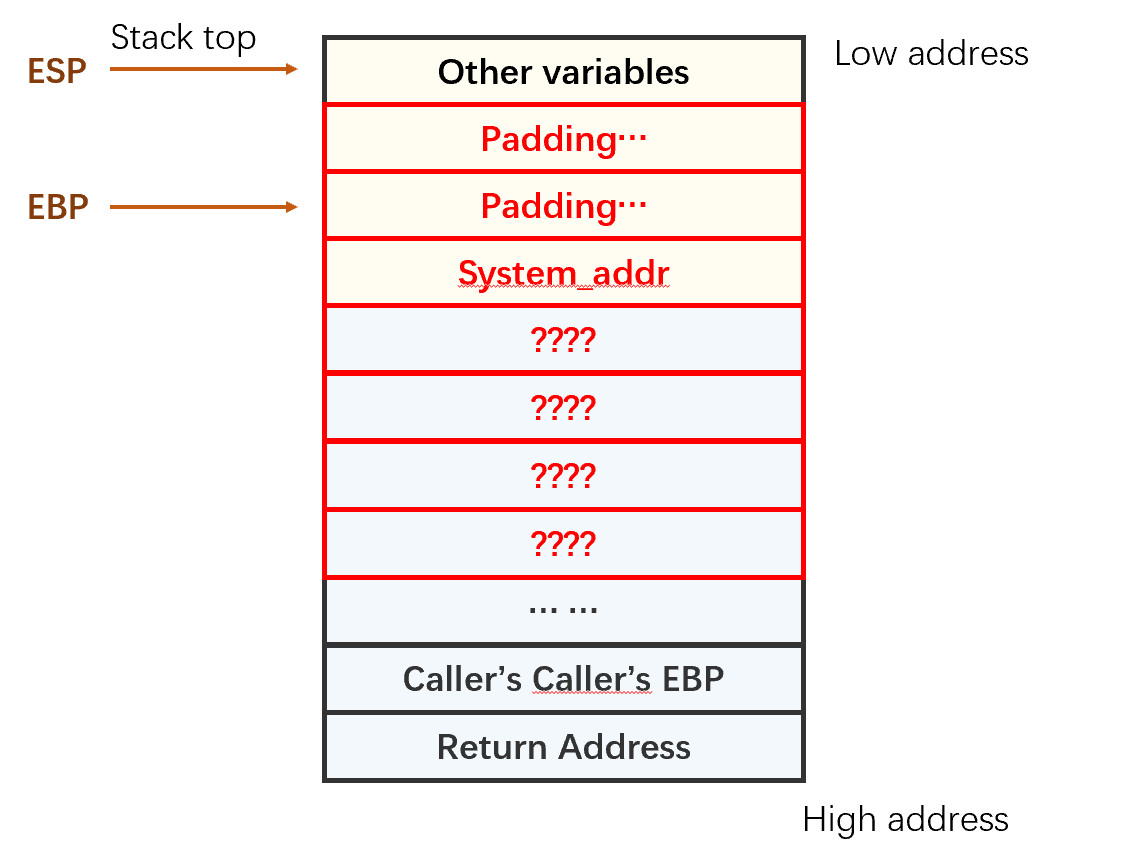
如果我们把返回地址修改为system函数,就可以执行任意命令行命令。
那么system函数的参数怎么控制?
如果要求system函数返回之后,再调用其他函数,该怎么做?
三、ROP技术
x86下的ROP(32位)
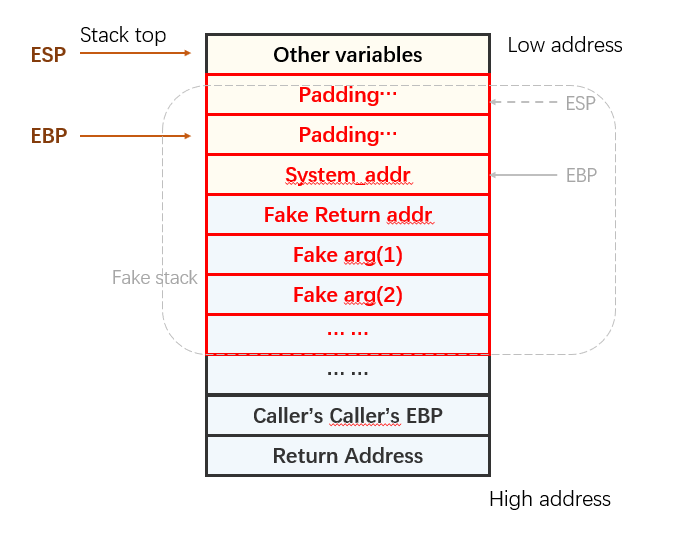
将Return Address修改为 System_addr,在跳转到system执行时,EBP指向原先的Return Address位置,故原先的Return Address下方是system返回后的执行地址,调用参数以此类推。
x64下的ROP
linux_64与linux_86的区别主要有两点:
- 内存地址的范围由32位变成了64位:可以使用的内存地址不能大于0x00007fffffffffff,否则会抛出异常。
- 函数参数的传递方式发生了改变:x86中参数都是保存在栈上,但在x64中的前六个参数依次保存在RDI,RSI,RDX,RCX,R8和 R9中,如果还有更多的参数的话才会保存在栈上。
所以按照之前的方法,将函数的参数布置在栈上已经不行了,必须将参数布置到寄存器中。
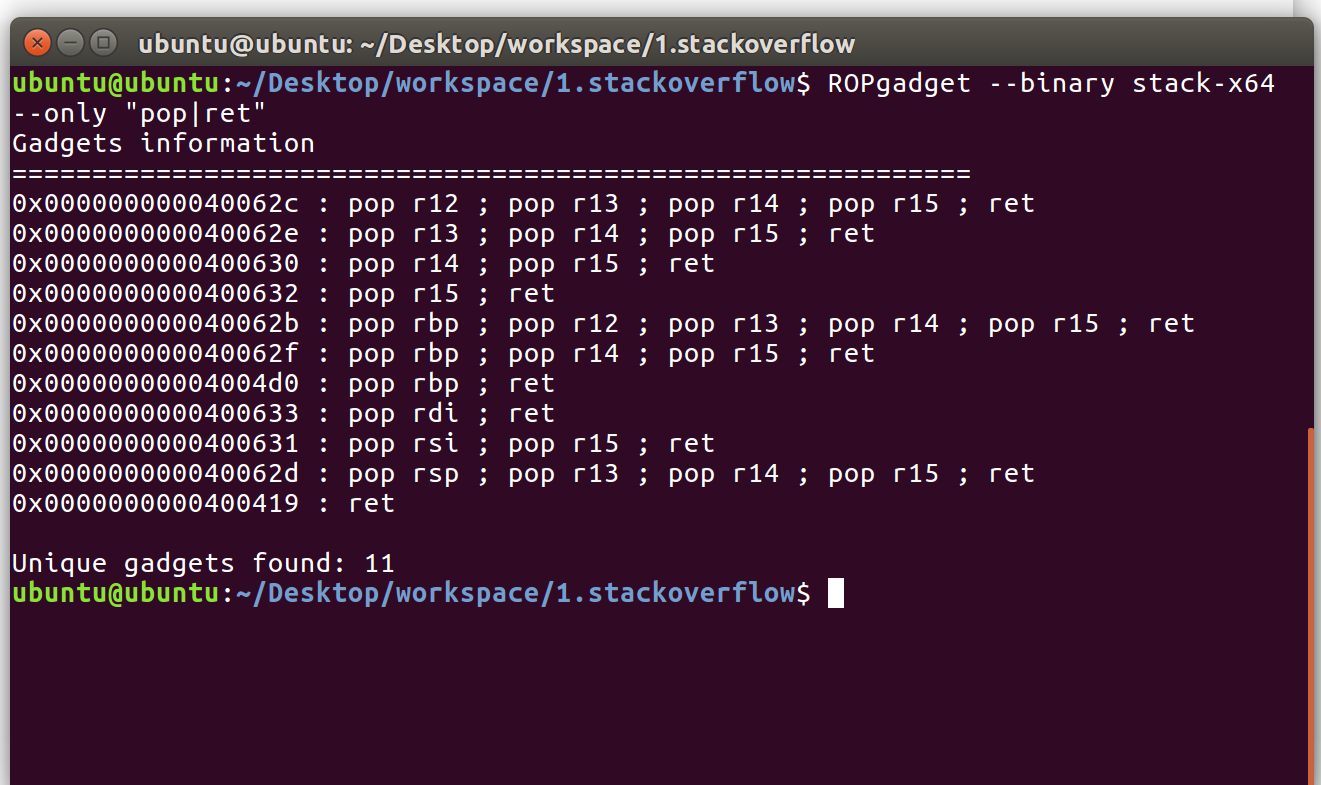
ROPGadget
一些程序的片段(Gadget)能帮我们设置寄存器。我们用工具ROPGadget来找到这些有用的片段。